Overview
The Website connection allows Qontext to crawl public web pages and ingest their text content into your Context Vault. Supported content:| Crawl type | Description |
|---|---|
Single Page | Crawls only the specific URL provided. Best for individual articles or pages |
Deep Crawl | Crawls the URL and follows all internal links. Best for entire sites or documentation |
| Content | Description |
|---|---|
Videos | Video files and embedded video content |
Restricted sites | Some websites (e.g. LinkedIn) block automated crawling and cannot be ingested |
Setting up the connection
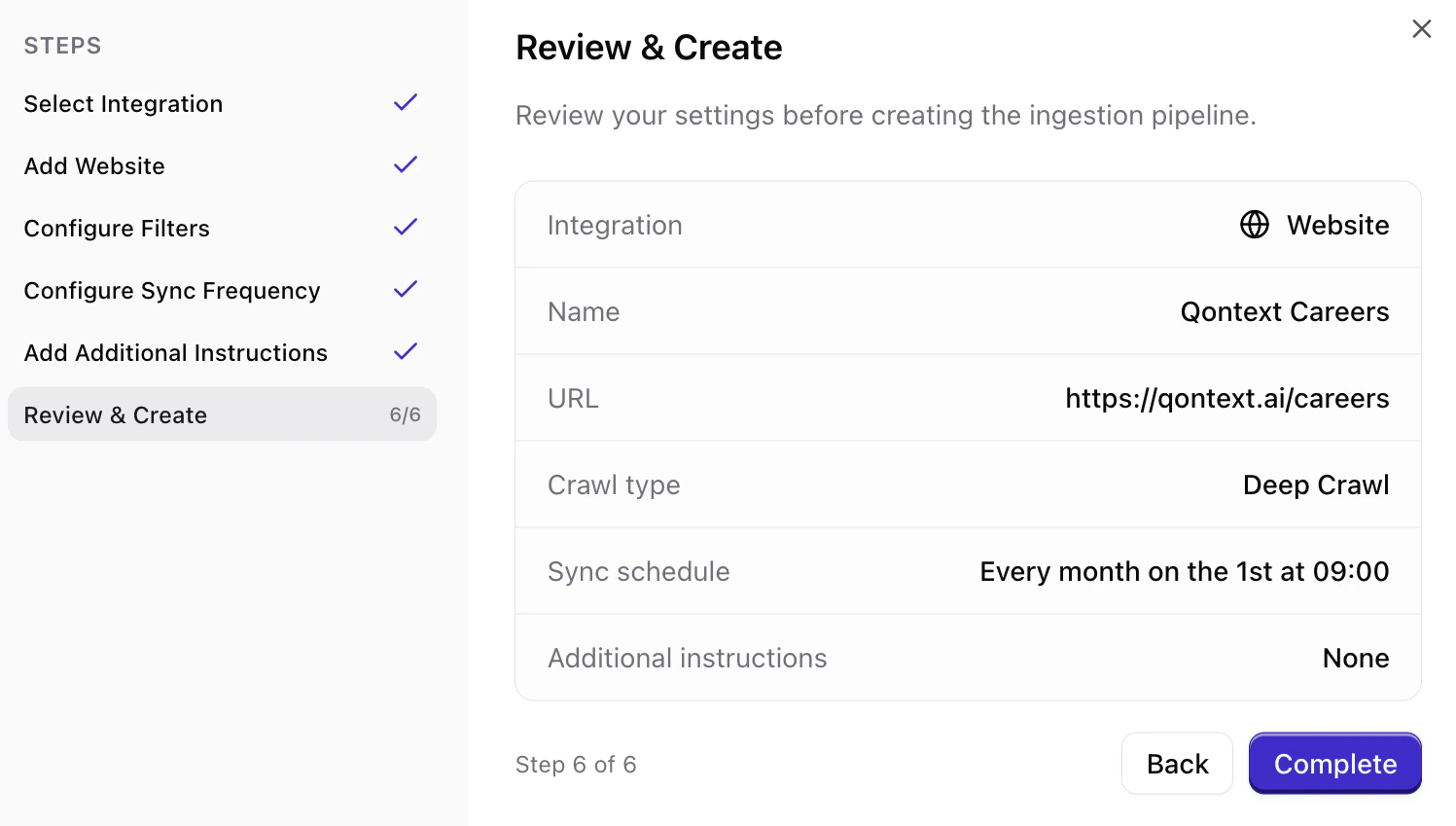
You can add a website from your Qontext vault, enter the URL, choose a crawl type, and set a sync schedule. The steps below walk you through the full flow.Open Data Sources in your vault
In the Qontext app, open the vault where you want website data to be ingested, then go to the Data Sources tab and click + Add.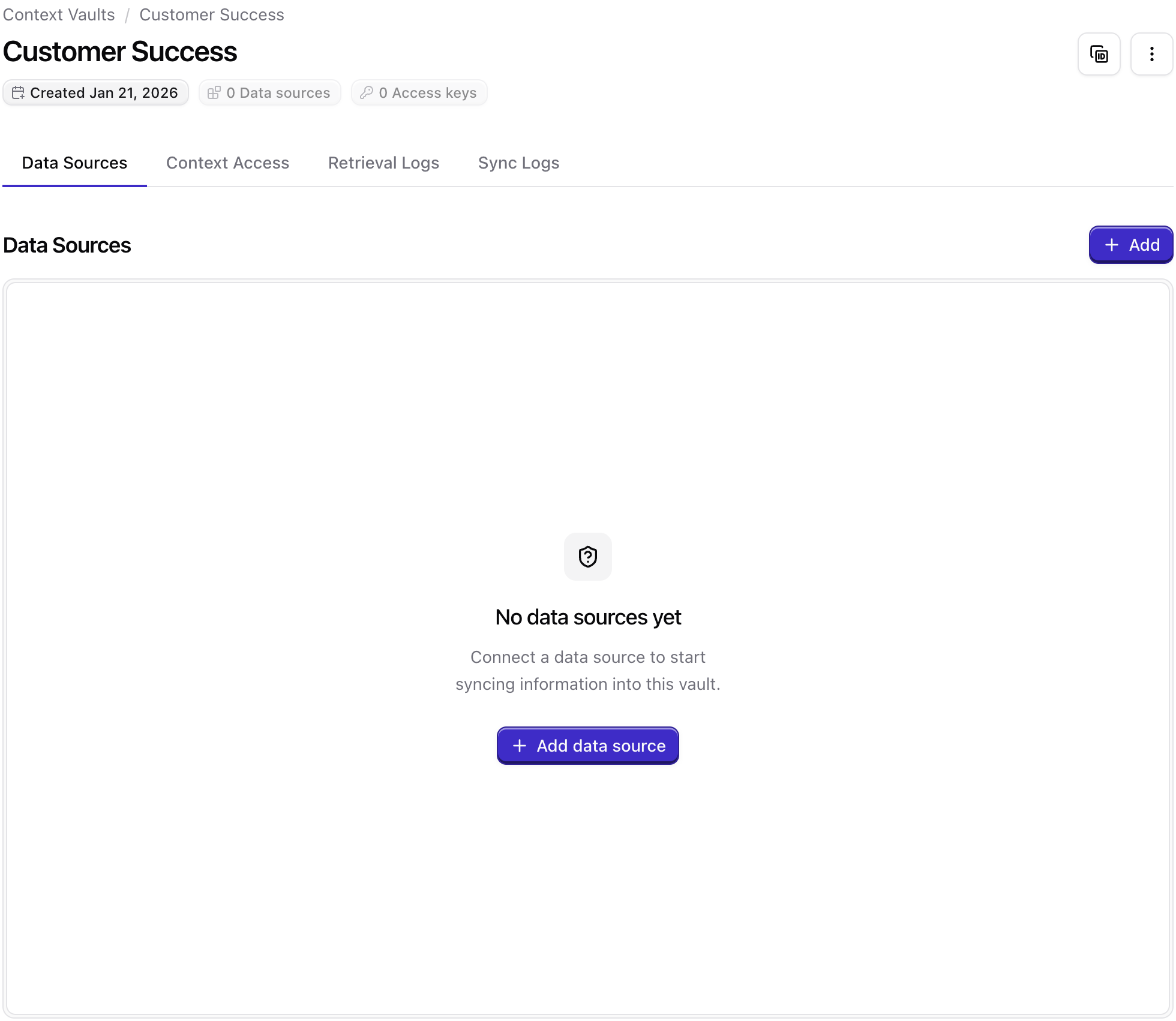
Select Website as the data source
Choose Website from the list of available data sources. This starts the website connection flow.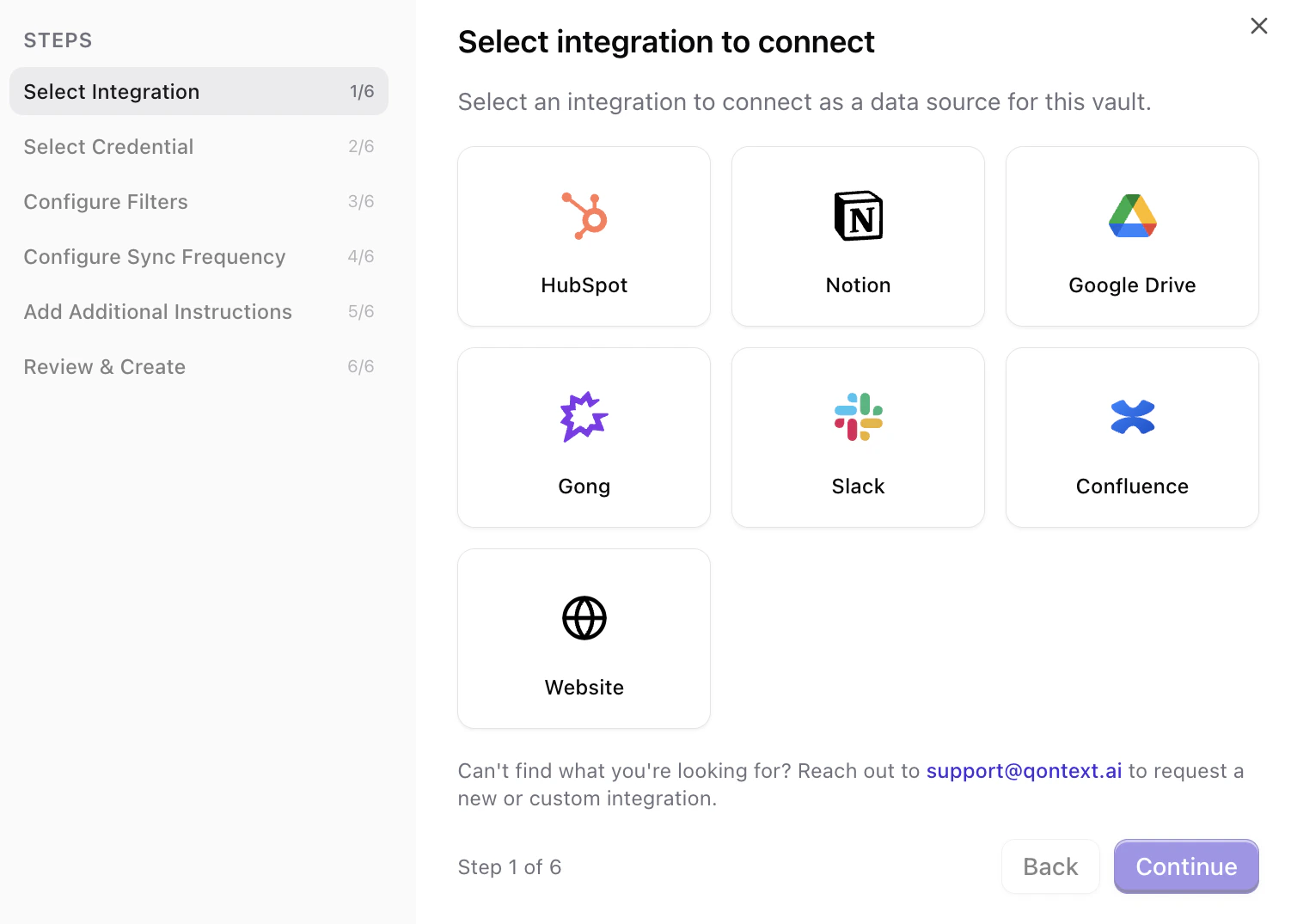
Enter the website URL
Give the website a name, which will be displayed on the Data Sources table. Then, enter the website URL you want to crawl. HTTPS is assumed by default; for HTTP sites, enter the full URL.URLs used in other vaults are shown for reference. URLs already connected to this vault are displayed and cannot be connected again, but the crawl type of an already ingested website can be edited in the Data Sources tab.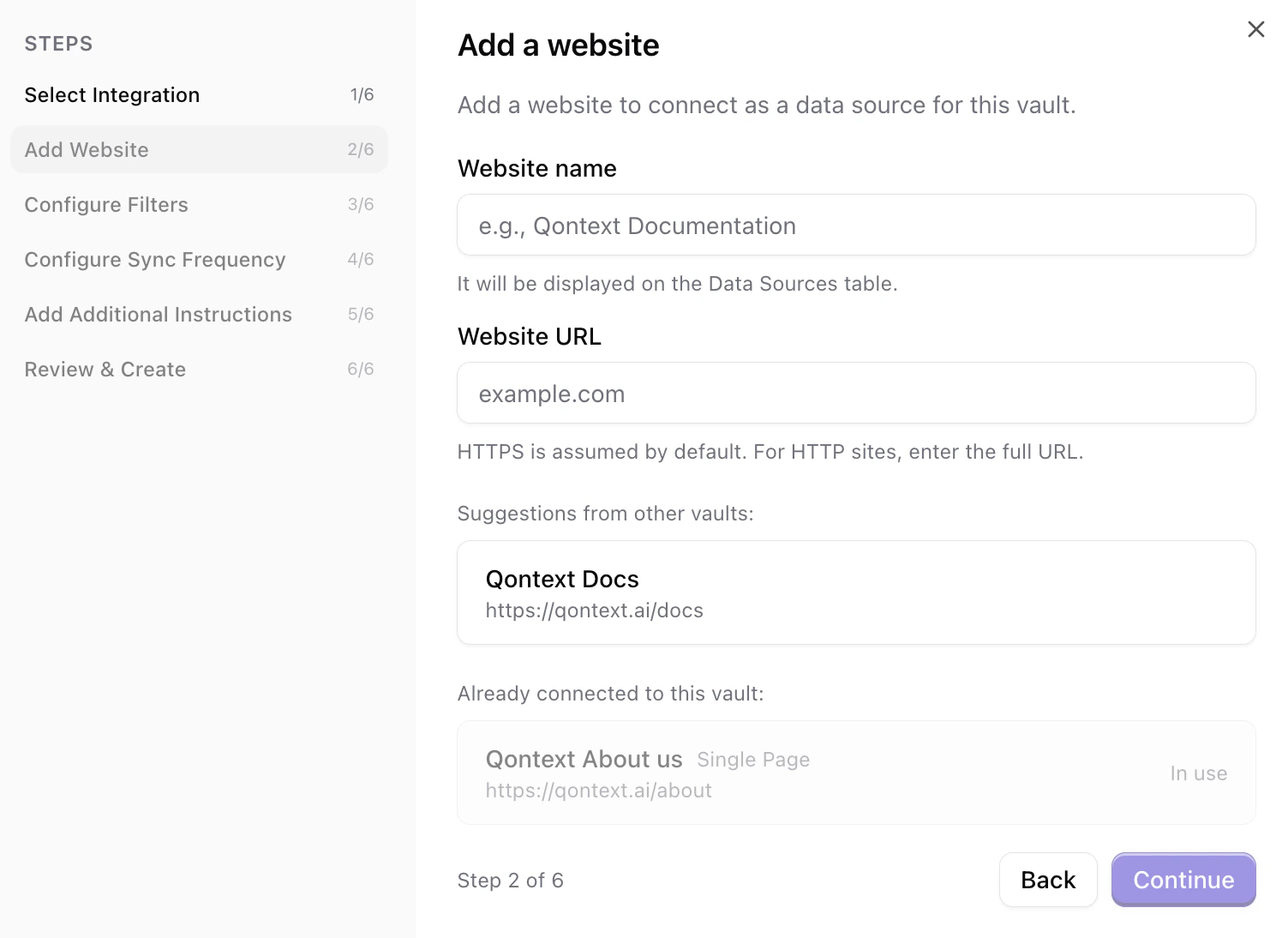
Choose crawl type
Select how the website should be crawled. Single Page crawls only the specific URL provided and is best for individual articles or pages. Deep Crawl crawls the URL and follows all internal links, making it best for entire sites or documentation.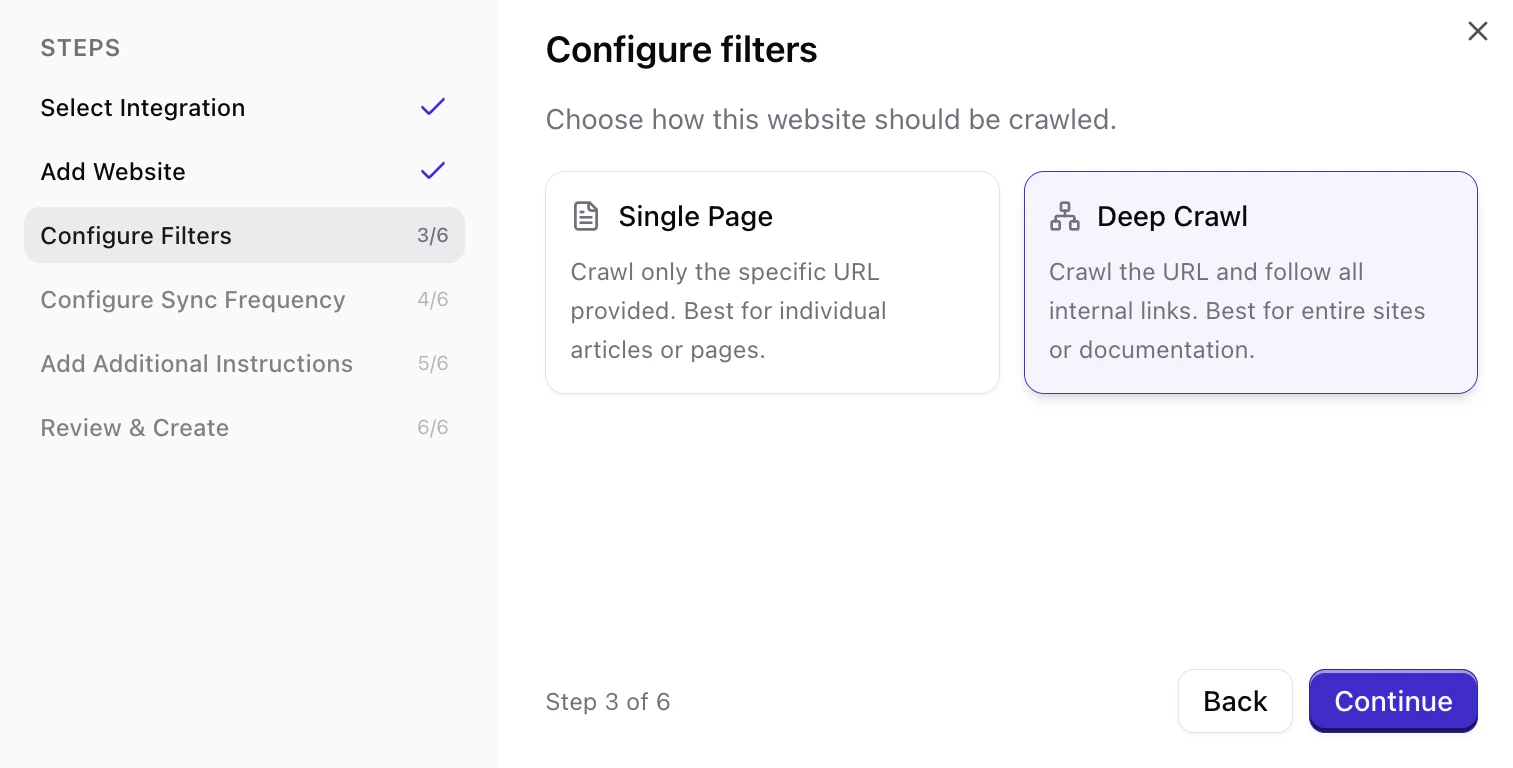
Set sync frequency
Choose how often Qontext should re-crawl the website (e.g. daily, weekly, monthly). More frequent syncs keep the vault up to date but use more resources.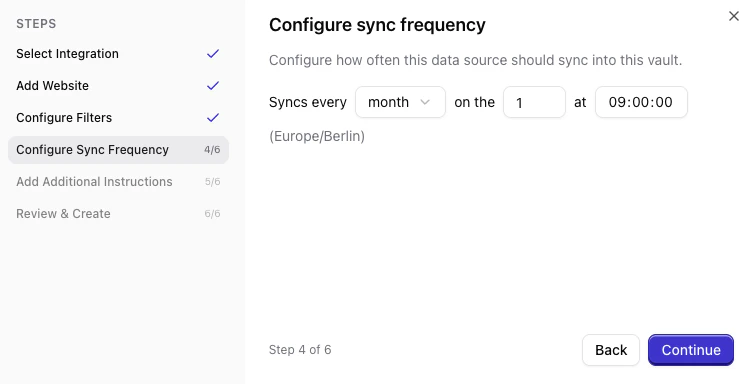
Set ingestion instructions (optional)
You can add ingestion instructions that tell Qontext how to interpret or prioritize the crawled content. This step is optional.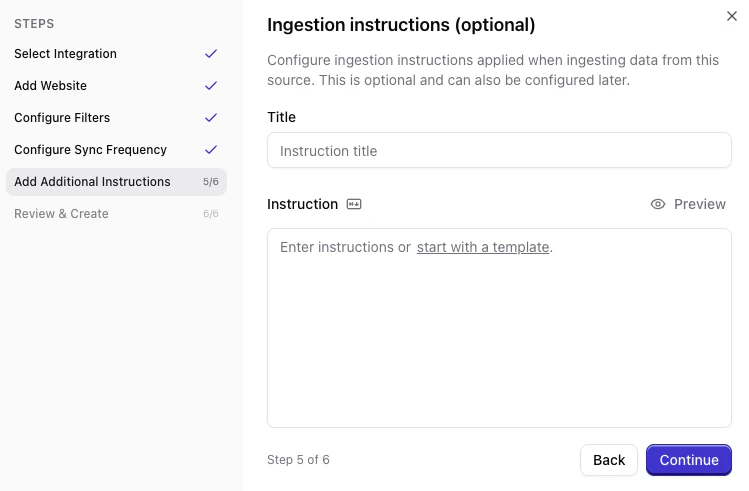
Sync latency
The crawl time depends on the crawl type and the size of the website. Most can be ingested within minutes.FAQ
When should I use Single Page vs Deep Crawl?
When should I use Single Page vs Deep Crawl?
Use Single Page when you want to ingest a specific article, blog post, or landing page. Use Deep Crawl when you want to ingest an entire site or documentation portal. Qontext will follow all internal links starting from the URL you provide.
How many pages does a Deep Crawl include?
How many pages does a Deep Crawl include?
A Deep Crawl follows up to 100 pages starting from the provided URL. If you need to limit the scope, consider using Single Page for specific URLs instead.
Can I add multiple websites to the same vault?
Can I add multiple websites to the same vault?
Yes. You can add as many website connections as you need from the Data Sources tab. Each website is a separate data source with its own crawl type and sync schedule.
What happens if a page is removed from the website?
What happens if a page is removed from the website?
If a previously crawled page is no longer accessible, it will not be updated during the next sync. Content already ingested remains in your vault. For data removal, contact support@qontext.ai.
Is the crawled content kept up to date?
Is the crawled content kept up to date?
Qontext re-crawls the website based on the sync frequency you set (daily, weekly, or monthly). Each sync picks up the newest version of the pages and discovers new pages (for Deep Crawl).